
Andrew Kae
Ph.D. Computer Science
University of Massachusetts, Amherst
Email: andrew.kae at gmail.com
Resume: [link]
Ph.D. Computer Science
University of Massachusetts, Amherst
Email: andrew.kae at gmail.com
Resume: [link]
My research interests lie primarily in machine learning and computer vision. My work focuses on semantic labeling, which is the task of assigning category labels (such as sky or road) to pixels in an image. In the past, I have also worked in document-specific modeling for use in character recognition.
I am currently a Research Engineer at Apple.

We propose a generative adversarial network (GAN) architecture for automatic image compositing. Experimental results on both synthesized images and real images show that our model can automatically generate more realistic composite images compared to several state-of-the-art methods.
PDF
We perform segmentation on videos in the YouTube Faces Database into one of three class (hair, skin, or background). We extend previous work by incorporating a conditional restricted Boltzmann machine (CRBM) into a CRF framework for labeling face regions. The CRBM models shape and temporal dependencies while the CRF models local dependencies.
PDF Supplementary
We combine an RBM and a CRF to label superpixel regions in a face image as one of three classes (hair, skin, or background). The RBM provides global shape information while the CRF models local interactions among adjacent superpixels.
PDF Project Page Data
We derive a set of landing page and OCR features to help categorize display ads according to a taxonomy. This can be useful in an active learning setting or as additional features in a ranking system for display ad selection.
PDF
We use a third party OCR system to first get an initial translation of a document. Afterward, our algorithm selects a subset of these translated words which are believed to be correctly translated with high confidence, which we call the clean set. We then use this clean set as training data to improve on the original OCR accuracy. We also introduce a bound for including a mistaken translation into the clean set.
PDF (Conference) PDF (Journal) Tech Report
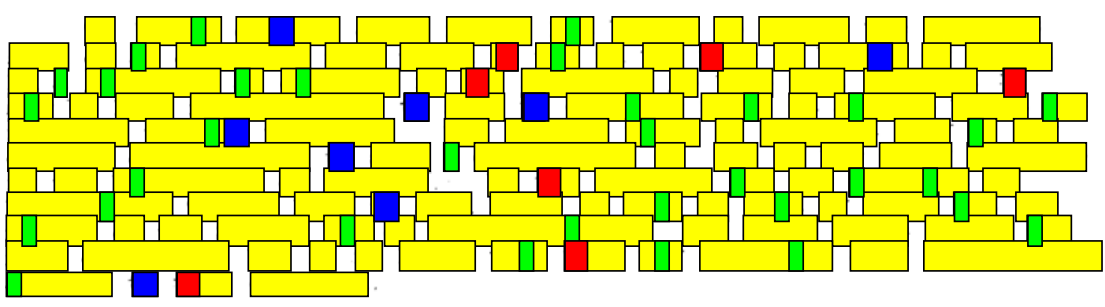
We use a cryptogram-style decoding algorithm for recognizing a document without using any previous font models. We first used this approach on an English document and later applied it to a Greek document.
PDF (Conference) PDF (Journal)Imagine you are shopping for beer at the supermarket. There may be 50 or more different types of beer on the shelf and you only know of several brands. You would like to try something new but you are not sure which one. We propose taking a picture of all the beers with your cameraphone and see all the reviews and recommendations, to help you make a better, more informed decision.
LinkWe present applications of deep learning at Curalate. In particular we present Intelligent Product Tagging, which is an automated way to match products (such as bags, shoes) in a photo to the corresponding products in a catalog. We also present other interesting applications of deep learning for tasks in computer vision, such as image colorization, photorealistic style transfer, and caption generation.
Link Slideshare LinkI grew up in New York and graduated from Stuyvesant High School. I then completed my B.A. and M.Eng in Computer Science at Cornell University. I worked with Professor Claire Cardie during my M.Eng in Opinion Annotation. Later, I worked with Professor Ralph Grishman at NYU doing work in Event Annotation.
I then completed my Ph.D. in Computer Science at UMass Amherst working with Professor Erik Learned-Miller. During this time, also completed an internship at Yahoo Labs! and participated in a NSF EAPSI fellowship in Japan working with Professor Koichi Kise at Osaka Prefecture University.
